通过官方文档http://www.sequoiadb.com/cn/inde ... 190712&edition_id=0 中描述,使用
[list=1]
[*]scala>sqlContext.sql("CREATE TEMPORARY TABLE datatable USING com.sequoiadb.spark OPTIONS ( host 'serverX:11810,serverY:11810', collectionspace 'test', collection 'data')")
[/list]
连接巨杉数据库,当连接的表为“分区表”时,使用分区列查询时会全表扫描,并没有使用到分区后的小表
======================================================================
例如使用如下方式连接sdb,指定连接的小表为flow0801,查询速度非常快:
CREATE temporary table datatable ( src_ip string,dst_ip string, dt string ,time string) using com.sequoiadb.spark OPTIONS ( host 'xxxx:11810', collectionspace 'hgsc201508', collection 'flow0801')
如果修改为如下方式连接sdb后,再使用SQL语句查询,消耗时间超长,经排查是触发了全表扫描
CREATE temporary table datatable ( src_ip string,dst_ip string, dt string ,time string) using com.sequoiadb.spark OPTIONS ( host 'xxxx:11810', collectionspace 'hgsc', collection 'flow')
select * from datatable where dst_ip='100.10.40.121' and dt=2015080801
======================================================================
使用的表为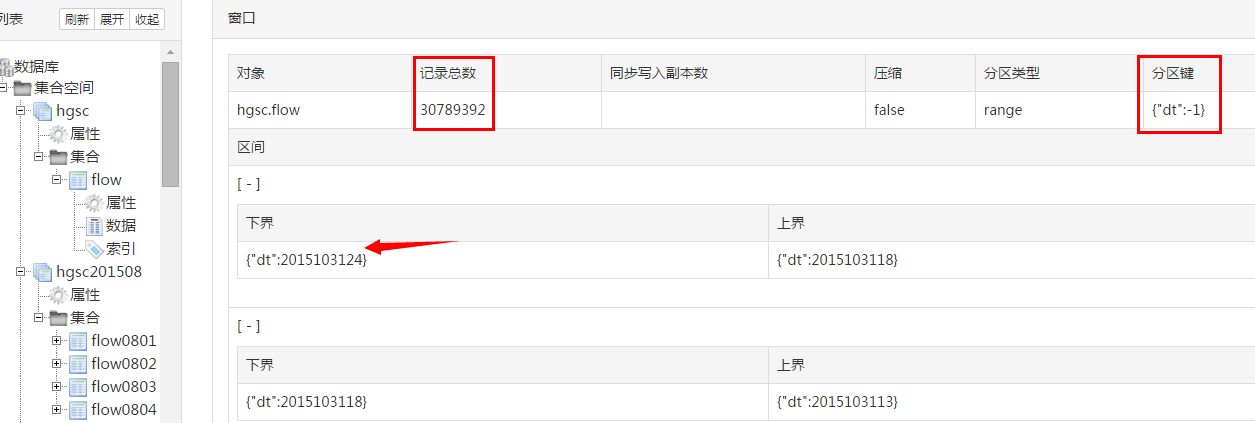 其中 hgsc.flow是大表, 在这个表上做了物理分区。
其中 hgsc.flow是大表, 在这个表上做了物理分区。
使用的spark驱动源代码来源:https://github.com/SequoiaDB/spark-sequoiadb