突然看到这个问题,让我很是感兴趣,因为近两天,我的环境已经被这个 -222 错误困扰。
首先这个 -222 错误,实际上就是 SDB 底层的节点(coord 、catalog 、 datanode) 在比对收到的请求和自身的记录的数据版本,或者是整个集群的版本时,发现版本不对,而导致的错误。
简单的说,就是本应该请求要发给 A 的,消息却错误的发给了 B ;
B 自己一看这个请求,和我自己的记录不对啊,消息中明明说是给 A 的;
然后DB 就抛出这个异常了。
**** 分割一下 ******
我先介绍我的环境。
在个人机器上搭建的一个虚拟机集群,然后通过 拷贝镜像的方式,复制了三台机器,然后就开始了集群的部署。
当时部署时没有特别注意,都是正常流程,但是现在回想起来,当时集群部署时,就已经老出现问题,但是我通过自己的各种骚操作,都将问题给规避了。
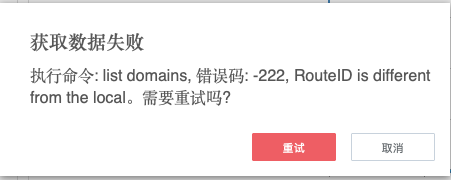
集群是顺利搭建起来了,但是 SAC 经常性抽风,报错 -222, 有时候甚至连页面都无法打开。
计算机都是死物,没有无缘无故的爱,也没有无缘无故的恨,肯定是出问题了。
我最喜欢解决问题了,所以就开始较上劲了。
**** 分割一下 ******
首先看coord 日志,从日志中,你会发现大量这种错误
2020-07-31-15.48.11.028348 Level:ERROR
PID:1748 TID:3445
Function:forward Line:175
File:SequoiaDB/engine/coord/coordAuthBase.cpp
Message:
Failed to execute command[7000] on node[{ GroupID:1, NodeID:1, ServiceID:3(CATA) }], rc: -222
2020-07-31-15.48.11.028365 Level:ERROR
PID:1748 TID:3445
Function:authenticate Line:392
File:SequoiaDB/engine/pmd/pmdExternClient.cpp
Message:
Client[10.211.55.21:33716-Extern] authenticate failed[user: ], rc: -222
2020-07-31-15.48.11.028374 Level:ERROR
PID:1748 TID:3445
Function:processMsg Line:2189
File:SequoiaDB/engine/pmd/pmdProcessor.cpp
Message:
Error processing Agent request, rc=-222
2020-07-31-15.48.11.028416 Level:WARNING
PID:1748 TID:3445
Function:_onMsgEnd Line:335
File:SequoiaDB/engine/pmd/pmdSession.cpp
Message:
Session[10.211.55.21:33716] process msg[opCode=7000, len: 89, TID: 3445, requestID: 1959] failed, rc: -222
没有什么营养的错误信息。
但是仔细翻查,还是有一些有用的信息,例如
2020-07-31-15.28.33.117113 Level:ERROR
PID:1748 TID:1925
Function:connect Line:752
File:SequoiaDB/engine/oss/ossSocket.cpp
Message:
Failed to complete connect, rc = -13
2020-07-31-15.28.33.117119 Level:ERROR
PID:1748 TID:1925
Function:syncConnect Line:345
File:SequoiaDB/engine/net/netEventHandler.cpp
Message:
Connection[Handle:12] connect to sdb2:11823(11823) failed, rc: -13
2020-07-31-15.28.33.117136 Level:WARNING
PID:1748 TID:1925
Function:_sendToCatlog Line:492
File:SequoiaDB/engine/coord/coordCB.cpp
Message:
Send message to primary catalog[1, 2, 3] failed[rc: -13]
2020-07-31-15.28.33.808674 Level:ERROR
PID:1748 TID:1925
Function:_complete Line:1282
File:SequoiaDB/engine/oss/ossSocket.cpp
Message:
failed to connect to remote, errno: 113( No route to host )
2020-07-31-15.28.33.808712 Level:ERROR
PID:1748 TID:1925
Function:syncConnect Line:345
File:SequoiaDB/engine/net/netEventHandler.cpp
Message:
Connection[Handle:13] connect to sdb2:11823(11823) failed, rc: -79
从这些错误中,我们可以发现,首先出现了 网络错误,-13 (网络超时),errno:113 (linux 错误码,代表网络不通),还有和 sdb2 机器的数据节点连接出现了断开。
我们继续检查 sdb2 的11820 节点 (catalog) 日志
2020-07-29-16.23.34.787329 Level:ERROR
PID:8770 TID:8785
Function:_checkBreak Line:1172
File:SequoiaDB/engine/cls/clsReplicateSet.cpp
Message:
vote: primary [node:1] alive break(unknown)
这个 node:1 就是刚才 coord 节点的机器啊,也出现了 sdb2 无法连接 sdb1 的错误 (心跳断开了)
**** 分割一下 ******
从自己最基础的设置开始思考,网络相关的设置
防火墙 【关闭】
SELinux 【关闭】
ulimit open file 【设置 65535】
到这里,我自己就开始反思,是否因为虚拟机是通过 克隆出来的,导致了问题?
我自己在配置 虚拟机时,已经重新生成了 MAC 地址,理论上通过 ifconfig 也能够看到网卡是使用最新的 MAC 地址,应该不至于,但是为了保险起见,我自己又给 网卡的配置文件中,直接写上了 MAC 地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
增加了 HWADDR=00:1c:42:db:01:13
重启了网卡服务,感觉回来了,自己心里美滋滋,觉得解决了一个难题。
**** 分割一下 ******
但是苍天对我不公,第二天,SAC 依然报错 -222
我瞬间就觉得手里的饼不香了,继续努力。
逐一检查,基本上linux 的网络优化都没有做,所以出厂配置应该都是好的。
突然自己灵机一动,是否会是拷贝的虚拟机,之前的环境有污染?
我首先想到的就是 nginx 和 keepalived。
通过ps 发现果然之前已经安装了 nginx 和 keepalived。
$ systemctl status nginx.service
● nginx.service - nginx - high performance web server
Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled)
Active: active (running) since 五 2020-07-31 15:30:12 CST; 32min ago
Docs: http://nginx.org/en/docs/
Process: 6217 ExecStop=/bin/kill -s TERM $MAINPID (code=exited, status=0/SUCCESS)
Process: 6219 ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf (code=exited, status=0/SUCCESS)
Main PID: 6220 (nginx)
Tasks: 2
CGroup: /system.slice/nginx.service
├─6220 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
└─6221 nginx: worker process
$ systemctl status keepalived.service
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled)
Active: active (running) since 五 2020-07-31 15:44:37 CST; 18min ago
Process: 31773 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 31774 (keepalived)
Tasks: 3
CGroup: /system.slice/keepalived.service
├─31774 /usr/sbin/keepalived -D
├─31775 /usr/sbin/keepalived -D
└─31776 /usr/sbin/keepalived -D
$ ps -ef | grep keepalived
root 1977 3460 0 16:03 pts/1 00:00:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn keepalived
root 31774 1 0 15:44 ? 00:00:00 /usr/sbin/keepalived -D
root 31775 31774 0 15:44 ? 00:00:00 /usr/sbin/keepalived -D
root 31776 31774 0 15:44 ? 00:00:00 /usr/sbin/keepalived -D
ps 查看 keepalived 也没有看到 conf 配置 ,心想:难道是 keepalived 是没有配置完?仅仅装上了? $KEEPALIVED_OPTIONS 参数也没有好好设置。
,心想:难道是 keepalived 是没有配置完?仅仅装上了? $KEEPALIVED_OPTIONS 参数也没有好好设置。
想想头大,翻看自己过去的笔记,理论上 conf 配置文件的路径应该在 /usr/local/etc/keepalived/keepalived.conf,但是这个环境没有
再仔细的翻,发现自己在最开始时,conf 路径在 /etc/keepalived/keepalived.conf
vi /etc/keepalived/keepalived.conf 一看,头都大了
$ cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lvs-01
}
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 3
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
将 track_script 块加入 instance 配置块
track_script {
chk_nginx ## 执行 Nginx 监控的服务
}
virtual_ipaddress {
10.211.55.23
}
}
keepalived 的虚拟机地址为 10.211.55.23
这个时候再看 ip a 命令的结果
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:1c:42:1b:c4:eb brd ff:ff:ff:ff:ff:ff
inet 10.211.55.21/24 brd 10.211.55.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 10.211.55.23/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fdb2:2c26:f4e4:0:21c:42ff:fe1b:c4eb/64 scope global mngtmpaddr dynamic
valid_lft 2591771sec preferred_lft 604571sec
inet6 fe80::21c:42ff:fe1b:c4eb/64 scope link
valid_lft forever preferred_lft forever
好家伙,自己给自己挖了一个坑,因为我在克隆了虚拟机后,给三台机器分配的 IP 地址是
10.211.55.21 sdb1
10.211.55.22 sdb2
10.211.55.23 sdb3
IP 地址冲突了
**** 分割一下 ******
问题定位到这里就结束了,解决方法很简单
1 直接关闭 keepalived 服务
2 或者修改 keepalived 的虚拟 IP 地址
3 修改 服务器的 IP 地址
**** 分割一下 ******
这次真的是自己给自己挖了一个坑,但是整个问题定位下来,还是很有意思的,再次坚定了我对计算机的认识
它真的很傻,不可能突然自己就抽风,它要抽风,肯定是我们自己给他抽了一巴掌,所以生活就会给你回抽一巴掌,让你知道知道:”什么叫体统“!!!

